What is a chatbot? A chatbot is an assistant for answering questions, saving time from waiting human’s responses. But how? How computer can understand human language? Indeed, it can’t read words like we do. It reads number. Therefore, how to transform words into numbers is crucial for using languages to communicate with computers.
Data Preprocessing
Depending on what kind of chatbot to build, the collection of data can range from open source platform, scraping from websites, accessing to APIs from data vendor. It may includes labels for doing classification problems. If not, having some domain knowledge is important to do proper labelling.
Then, based on what models to use, the data cleaning process also needs some trial and error. Nevertheless, it usually includes removing punctuation, stop words, and special characters. We can set up a rough preprocessing first and evaluate model performance by splitting data into training, validation and test set. This process iterates over and over until getting an acceptable model performance.
Feature Extraction
Bag-of-Words
There are some methods to transform words into numbers. For example, assigning each word with a unique number. Let’s say if we have a sentence “It is a beautiful day!”. The sentence can be represented by numbers like “0 1 2 3 4 5”. This transformation is called encoding. The exact procedure is as follows
- Tokenize sentences
- Create a vocabulary containing all words
- Encode a sentence as a vector with size equivalent to vocabulary size
Here is a snippet for demonstration
import numpy as np
from nltk.tokenize import word_tokenize
def generate_BOW(sentences: list, tokenizer):
vocab = set([j for i in sentences for j in tokenizer(i)])
for sentence in sentences:
words = tokenizer(sentence)
bag_vector = np.zeros(len(vocab))
for w in words:
for i, word in enumerate(vocab):
if word == w:
bag_vector[i] += 1
print(f"{sentence}\n{bag_vector}\n")
sentence_list = ['It is a beautiful day!', 'Anyone wants to go out for an adventure?', 'It is going to be interesting!']
generate_BOW(sentence_list, word_tokenize)
The encoded sentences are
It is a beautiful day!
[1. 0. 1. 0. 0. 0. 1. 1. 0. 0. 0. 0. 0. 0. 0. 1. 0. 1.]
Anyone wants to go out for an adventure?
[0. 1. 0. 1. 1. 0. 0. 0. 1. 1. 0. 1. 1. 1. 0. 0. 1. 0.]
It is going to be interesting!
[1. 0. 0. 0. 0. 1. 0. 1. 1. 0. 1. 0. 0. 0. 1. 0. 0. 1.]
with vocabulary of this example
{'It', 'an', 'day', 'adventure', '?', 'going', 'a', 'is', 'to', 'for', 'be', 'Anyone', 'out', 'wants', 'interesting', 'beautiful', 'go', '!'}
This method is called Bag-of-Word algorithm. Since word/sentence is vectorized, we can use dot-product, cosine similarity as a metric to get the desired contents. It is usually used to compare similarity of sentences, documents. More frequent the word is, the bigger part it plays in the whole sentence/article. Here is a simple visualization by using wordcloud.
from collections import Counter
from wordcloud import WordCloud
from matplotlib import pyplot as plt
tokenized_list = [ j for i in sentence_list for j in word_tokenize(i)]
word_freq = Counter(tokenized_list)
wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(word_freq)
# Display the word cloud using matplotlib
plt.figure(figsize=(10,5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off") # Remove the axis
plt.show()

TF-IDF
However, some cleaning is necessary for getting rid of trivial word or symbol. This process needs some domain knowledge to carefully get the ideal results. Another algorithm, Term Frequency - Inverse Document Frequency(TF-IDF) is suitable fro resolving this issue. As the phrase implies, it consists of two parts, TF and IDF [1]. Term frequency, tf(t,d), is the relative frequency of term t within document d, $$ tf(t, d) = \frac{f_{t,d}}{\Sigma_{t^{’}\in d}f_{t^{’},d}} $$ where $f_{t,d}$ is the raw count of a term in a document, i.e., the number of times that term t occurs in document d. $$ idf(t, D) = log(\frac{N}{|{d\in D:t\in d}|}) $$ with
- N: total number of documents in the corpus N = |D|
- $|{d\in D:t\in d}|$: number of documents where the term t appears.
The inverse document frequency is a measure of how much information the word provides, i.e., if it is common or rare across all documents. Multiplication of these two terms gives weights to words, which distinguishes the importance between words in documents. This method is helpful for getting keywords in documents.
However, these two methods are not ideal for sentiment analysis problems since they may provide the same outcome with the sentences composed of same words with difference order. Like ‘Cancer destroying immune system’, ‘Immune system destroying cancer’.
BOW, TF-IDF are not ideal for this sentiment analysis problem since they may provide the same outcome with the sentences composed of same words with difference order, like ‘Cancer destroying immune system’, ‘Immune system destroying cancer’. Thus, We need an algorithm for understanding the context in order to correctly understand human’s intent.
Word Embedding
Dimension has its meaning. For example, dog and cat are similar in terms of animal category, i.e. one dimension, but they are not that similar in terms of sound category. The vectorization of previous methods does not take these factors into account. Hence, a systematic transformation of vector space is crucial for extracting relations between words. This mapping process is called embedding. It turns sparse vectors into dense vectors. It resolves issues of lacking connections between words/sentences.
However, creating a good word embedding from scratch is not easy. It needs tons of data to tune the coefficient of matrix(neural network). Adopting pre-trained word embeddings are much more cost-effective for generous use purpose, e.g. building a chatbot in our case. There are several word embeddings, such as Word2Vec, GloVe, fastText, ELMo, and BERT [2].
BERT
Bidirectional Encoder Representations from Transformers (BERT) is a multi-layer bidirectional Transformer encoder. The core concepts are Masked Language modelling (MLM) and Next Sentence Prediction (NSP).
MLM enables bidirectional learning from text by masking a word in a sentence. This training technique forces BERT to use words from both sides of masked word to fill the covered word. Interestingly, this is how human usually learns a language by considering the context.
NSP makes BERT understand the relationships between sentences. It is achieved by randomly connecting sentences with non-coherent ones.
Leveraging these two training techniques, the semantic knowledge is captured by the learned embeddings/representations. Making BERT an ideal pre-trained model for solving lots of NLP problems, like semantic analysis, question answering, text prediction, text generation, summarization,… and so on by adding one additional output layer of neuron network. It achieved new state-of-the-art results and even outperformed human on some tasks [3].
Hugging face’s blog BERT 101 explains it quite well and provides tutorial to implement it. Also, the most well-known chatbot is ChatGPT produced by OpenAI nowadays. Here is the response from it for answering how MLM works and demonstrating how to implement it.
LLM
A term becomes quite famous recently, since the release of ChatGPT. Large Language Model (LLM), it refers to a more advanced and powerful version of language model which is designed for understanding, generating text. LLM is often addressed extensive scale of training data and model parameter, GPT-3 for example.
LLMs (GPT-3, LlaMA 2, …) are autogressive models in NLP which generate outputs, one element at a time in a sequential manner. They are based on decoder part of Transformer architecture. It enables LLM to capture long-range dependencies and relationships in the input data. Then providing LLM the ability to generate coherent and contextually relevant text by considering the context of preceding tokens.
In contrast to BERT, LLMs are structured on decoder of Transformer. Without adopting encoder, it is more efficient to train models on large corpus in an autoregressive, unsupervised manner. It then can be fine-tuned for specific tasks. Here are some conversations with chatGPT for teaching me how GPT using decoder of Transformer to accomplish state-of-the-art results. The summarization is amazing for showing the difference between encoder and decoder of Transformer.
The autogressive model learned amount of knowledge on Internet. However, the outputs are mostly not quite useful for human. It hallucinates stuffs that are not existed, or just wrong. Hence, fine-tuned is needed and OpenAI published a paper [5] about how they get a well-behaved LLM. They introduce a mechanism called reinforcement learning from human feedback (RLHF) to instruct the model. They teach model the knowledge by giving them a dataset of labeler demonstrations of the desired model behavior, fine-tuning the model parameters by supervised learning, and then ranking the results from fine-tuned model, and further fine-tuning it through RLHF.
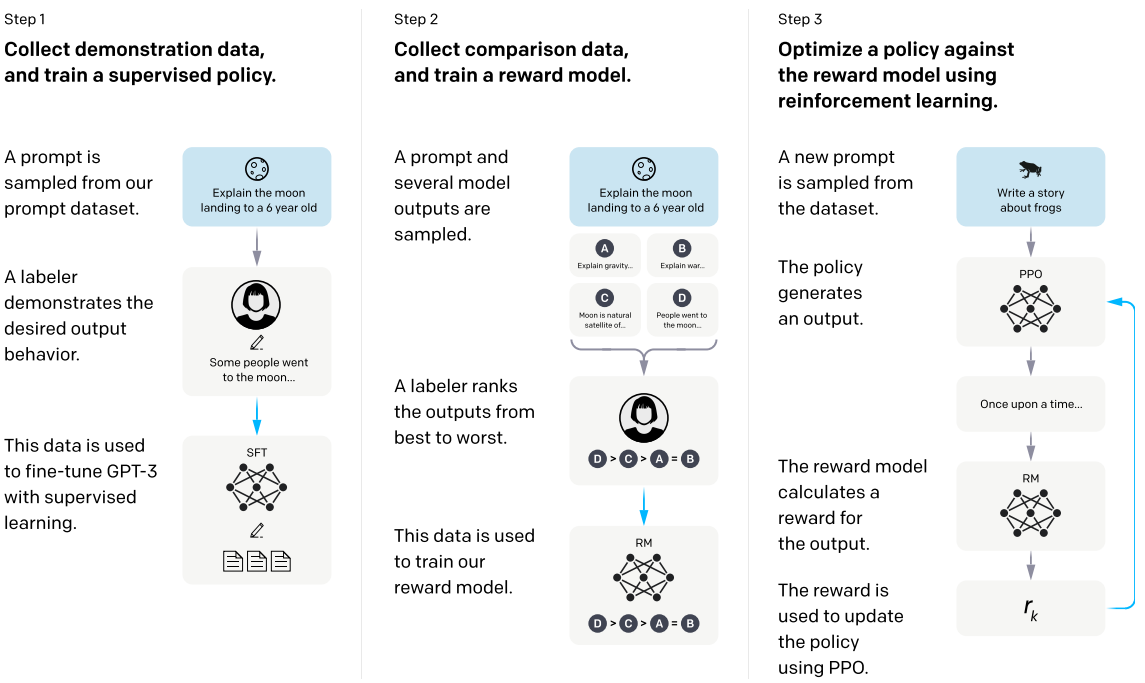
Through these fine-tuning procedure, the model performance boosts hugely even though the model parameters are comparably smaller than model without fine-tuning.
Model Evaluation
A query from user can be categorized into several domains, such as emotions, intents, or some specific FAQ dataset. A chatbot can be built based on customized FAQ dataset for providing answers to customers. The performance can be examined as classification problem of machine learning. The procedure is splitting the data into training, validation and test set and, using validation set for tuning hyperparameter and preventing overfitting, evaluating the performance on test set by metrics like accuracy, F1-score (suitable for unbalanced dataset). The similar procedure can be applied to analyze intents, emotions.
If similar search algorithm is used, like building a search engine for getting correct FAQ response or retrieval augmented generation (RAG) system for boosting LLM performance, metrics like hit rate, Mean Reciprocal Rank (MRR) are suitable for examining the model performance.
Deployment
Once ideal result from model is generated, it is ready to be deployed to production environment. One of deployment is setting up APIs for serving the model. It either can adopt GET request to pin the API endpoint with queries on url or use POST request to envelope the information and send it to the endpoints as JSON format.
Citation
Cite as
Ching, Jia-Hau. (Nov, 2023) “Creating a Chatbot”. JH’s Note.
Or
@article{ching2023chatbot,
title = "Creating a Chatbot"",
author = "Ching, Jia-Hau",
journal = "jiahau3.github.io",
year = "2023",
month = "Nov",
url = "https://jiahau3.github.io/posts/chatbot/"
}
Reference
[1] TF-IDF definition from Wikipedia
[2] Aakanksha Patil Top 5 Pre-trained Word Embeddings
[3] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[4] Muller, Britney “BERT 101 🤗 State Of The Art NLP Model Explained” Hugging Face Blog (2022)
[5] Ouyang et al. https://arxiv.org/abs/2203.02155 arXiv arXiv:2203.02155 (2022)